Vier Wege, wie Organisationen mit Vibe Coding umgehen
Tech-Leader diskutieren bei Vibe Coding nicht nur Tools — sie entscheiden, wer bauen darf, wer definiert was gebaut wird und wo Governance sitzt. Vier Operating Models für unterschiedliche Risikozonen.
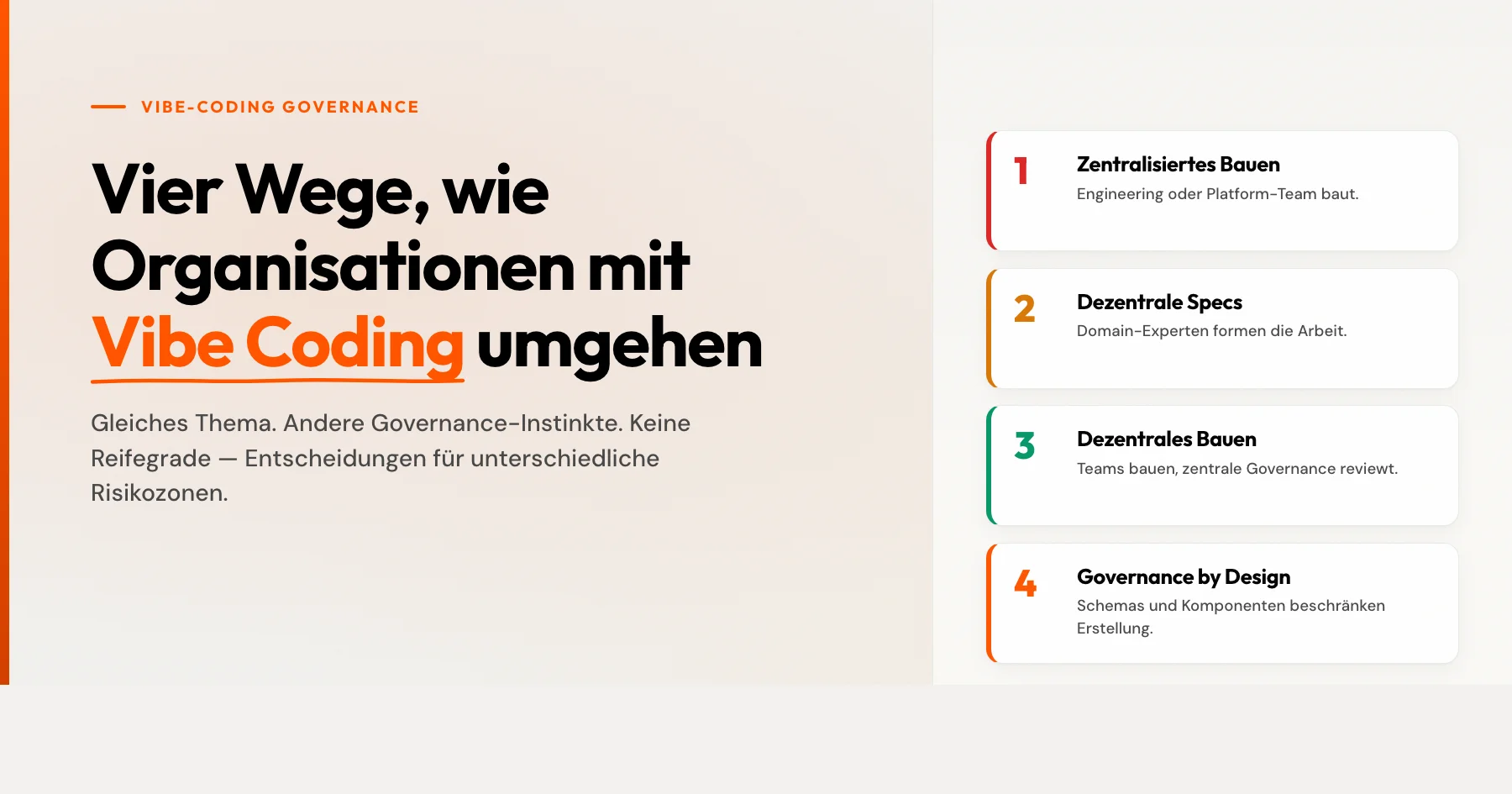
TL;DR: In den letzten Wochen habe ich Vibe Coding mit mehreren Tech-Leadern diskutiert. Mir ist aufgefallen: Teams streiten nicht nur über Tools. Sie entscheiden, wer bauen darf, wer definiert was gebaut wird und wo Governance sitzt. Ihre Antworten lassen sich in vier Operating Models gruppieren: zentralisiertes Bauen, dezentrale Specs, dezentrales Bauen mit zentraler Governance und Governance by Design. Das ist kein Ranking. Es ist eine Karte unterschiedlicher Entscheidungen für unterschiedliche Risikozonen.
Vor kurzem habe ich Vibe Coding mit mehreren Tech-Leadern diskutiert.
Ein CTO erzählte mir, sein Produktteam bringt inzwischen lauffähige Prototypen in Roadmap-Diskussionen — statt Slides. Ein Gründer fragte, ob Ops interne Tools direkt selbst bauen sollte. Eine Enterprise-Leaderin hatte die umgekehrte Sorge: Analysten experimentierten bereits mit AI-gebauten Workflows, die möglicherweise Kundendaten berühren.
Gleiches Thema. Sehr unterschiedliche Instinkte.
Genau darum geht es in diesem Beitrag.
Kein Urteil darüber, welcher Ansatz „richtig" ist. Eher eine Feldnotiz über die Governance-Muster, die ich immer wieder sehe.
Die Konversation startet meist beim LLM und der Plattform: Cursor, Claude Code, Lovable, Replit, v0, interne Agenten, MCP-Server.
Doch sie wird schnell organisatorisch:
Wer darf bauen, wer definiert was gebaut wird, und wo sitzt Governance?
Hier gehen die Meinungen scharf auseinander.
Manche halten AI-gestütztes Bauen innerhalb von Engineering. Manche lassen Domänen-Experten bessere Specs schreiben, halten die Implementierung aber zentral. Manche lassen Teams direkt bauen und governen den Output. Manche governen das Medium der Erstellung selbst — über Schemas, freigegebene Komponenten und Plattform-Beschränkungen.
Das sind keine Reifegrade.
Es sind Operating Models für unterschiedliche Risikozonen.
Wenn man sich nicht bewusst für eines entscheidet, bekommt man trotzdem eines per Default: Shadow AI, inoffizielle Prototypen, ungeprüfte Workflows und Governance per Slack-Thread.
Die Spannung: Erstellung hat sich vor Governance bewegt
AI hat die Erstellungsgeschwindigkeit von Engineering-Speed auf Idee-Speed verschoben.
Ein PM kann eine Workflow-Idee an einem Nachmittag in einen Prototyp verwandeln. Eine Analystin kann eine Datenpipeline an einem Wochenende zusammenbauen.
Eine Version davon will man, weil die Menschen am Problem oft den besten Kontext haben. Wenn sie diesen Kontext in lauffähige Artefakte verwandeln können, lassen sich mehr Ideen testen und Übergabeverluste reduzieren.
Aber Code berührt immer noch Daten. Interne Tools erzeugen immer noch Berechtigungsprobleme. Workflows brauchen immer noch Auditierbarkeit. Dependencies brechen immer noch. Und AI-generierter Code liefert weiterhin Defekte aus.
Veracodes „2025 GenAI Code Security Report" fand, dass 45% der getesteten AI-Coding-Outputs OWASP-relevante Schwachstellenklassen enthielten. Aikidos „State of AI in Security & Development 2026" berichtet, dass etwa jede fünfte Organisation einen ernsthaften Sicherheitsvorfall im Zusammenhang mit AI-generiertem Code erlebt hat — und dass viele Entwickler:innen Checks umgehen, ignorieren oder aufschieben, wenn sie die Auslieferung blockieren.
Der letzte Punkt ist wichtig.
Menschen umgehen Governance nicht, weil sie Governance hassen. Sie umgehen sie, wenn Governance langsamer ist als die Arbeit.
Vibe Coding vergrößert diese Lücke.
Die Frage ist also nicht: Sollen Organisationen Vibe Coding erlauben?
Die nützliche Frage lautet:
Welche Teile des Bauens werden dezentral, und welche bleiben zentral?
Modell 1: Zentralisiertes Bauen
Die erste Antwort ist simpel: dezentrales Bauen verbieten.
Nur zentrales Engineering oder freigegebene Plattformteams bauen Software, die innerhalb der Organisation läuft. Alle anderen dürfen anfordern, beschreiben oder priorisieren — aber nicht ausliefern.
Ownership bleibt klar. Architektur bleibt kohärent. Sicherheits-Gates bleiben dort, wo sie schon sind.
Für hochriskante Systeme kann das richtig sein: Identity, Finance, regulierte Kundendaten, Systems of Record, Infrastruktur, Deployment-Pipelines.
Der Trade-off liegt auf der Hand: Man behält Kontrolle, indem man Geschwindigkeit abgibt.
Die Menschen am Workflow übersetzen ihren Kontext weiterhin in Tickets und Priorisierungs-Meetings. AI macht Engineering vielleicht schneller — der organisatorische Bottleneck bleibt.
Zentralisiertes Bauen ist am sichersten, wenn die Kosten schlechter Software höher sind als die Kosten langsamer Software. Als unternehmensweite Antwort hat es aber ein Problem: Die Menschen werden trotzdem bauen. Nur eben außerhalb des offiziellen Pfads.
Modell 2: Dezentrale Specs, zentrales Bauen
Das zweite Modell lässt Domänen-Experten die Arbeit formen, hält die Implementierung aber zentral.
PMs, Analysten, Ops-Leads, Sales Engineers oder interne Agenten erzeugen bessere Inputs: klickbare Prototypen, Workflow-Maps, Test-Cases, Akzeptanzkriterien, Edge Cases, Permission-Annahmen, Beispieldaten, UI-States.
Engineering verwandelt diese Artefakte weiterhin in Produktivsysteme.
Dieses Modell wird unterschätzt.
Es verlangt nicht, dass jeder Domänen-Experte zum Production-Builder wird. Es verbessert das, was Engineering bekommt.
Statt eines vagen Jira-Tickets — „wir brauchen ein Onboarding-Dashboard" — bekommt das Team einen konkreten Workflow, Beispiele, erwartete States und Edge Cases.
Auch Agenten können helfen. Ein Produkt-Agent verwandelt Interviews in eine Spec. Ein QA-Agent entwirft Tests. Ein technischer Agent markiert Ambiguität, bevor Engineering startet.
Der Governance-Vorteil: Produktverantwortung bleibt zentral. Der Speed-Vorteil: Weniger Kontext geht verloren. Der Trade-off: Man hat den Input zum Bottleneck verbessert — aber der Bottleneck existiert weiter.
Dieses Modell funktioniert, wenn das Produktionsrisiko hoch ist, die Domänen-Ambiguität aber ebenfalls hoch. Lass die Kanten explorieren und spezifizieren. Lass die Mitte bauen und besitzen.
Modell 3: Dezentrales Bauen, zentrale Governance
Das dritte Modell verlagert das Bauen nach außen, hält Governance aber zentral.
Teams dürfen bauen. PMs, Analysten, Ops-Leads und Agenten können Tools, Workflows, Automatisierungen und Interfaces erzeugen.
Aber die Organisation definiert zentrale Regeln dafür, was laufen darf, was auf Daten zugreifen darf, was Review braucht und was blockiert wird.
Governance kann durch Menschen, Agenten oder beides erfolgen.
Menschliche Governance heißt: Architektur-Reviews, Production-Readiness-Checklists, Risk-Tiers, Ownership-Regeln und Sign-off.
Agentische Governance heißt: AI Code Review, Policy-as-Code-Gates, Dependency-Scanning, PII-Detection, Runtime-Monitoring, Guardrails für Modell-Calls und Merge-blockierende Agenten.
Viele Teams steuern auf dieses Modell zu, weil es nach dem pragmatischen Kompromiss aussieht:
Menschen bauen lassen. Kontrolle um den Output legen.
Der Reiz ist real. Man muss den Stack nicht neu designen oder jeden Workflow in eine Plattform zwingen. Man trifft Builder dort, wo sie sind, und legt Governance um die Arbeit.
Aber dieses Modell hat eine harte Frage:
Wer validiert den Validator?
Wenn ein menschliches Review-Board jedes AI-gebaute Tool freigibt, wird das Review-Board zum Bottleneck.
Wenn ein AI-Agent jedes AI-gebaute Tool validiert, erbt die Governance-Schicht eigene Failure Modes: übersehene Issues, False Positives, Policy-Drift.
Das macht das Modell nicht falsch. Es heißt: Das Modell braucht Ownership, Eskalation und Audit Trails.
Eine nützliche Regel: Der Governance-Agent darf blockieren, markieren und erklären. Ein benanntes Team besitzt weiterhin die Policy und die Produktentscheidung.
Dieses Modell funktioniert am besten für Low- und Medium-Risk-Bereiche, in denen Geschwindigkeit zählt: interne Tools, Workflow-Automatisierungen, Prototypen mit limitierten Daten, Team-Produktivitäts-Apps und Custom-Logic, die nicht in eine striktere Plattform passt.
Modell 4: Governance by Design
Das vierte Modell verändert das Erstellungsmedium selbst.
Statt jedem zu erlauben, beliebigen Code zu generieren und den Output hinterher zu prüfen, arbeiten Builder innerhalb begrenzter Systeme: Schemas, freigegebene Komponenten, deklarative Definitionen, berechtigte APIs, MCP-Tool-Grenzen, Regeln auf Plattform-Ebene.
Die Prämisse ist einfach:
Ungültige Zustände sollen schwer oder unmöglich erzeugbar sein.
Eine Fachbereichs-Userin schreibt keine React-Komponente, keinen API-Endpoint, keine Datenbank-Query, keine Access-Logik, keine Validierung und keine Tests. Sie definiert einen Workflow, ein Formular, einen Report oder einen Approval-Prozess in einem strukturierten Format.
Die Plattform validiert die Definition, der Renderer übernimmt das Interface, Berechtigungen steuern den Datenzugriff, und der Komponenten-Katalog definiert, was existieren darf.
Das ist Governance vor der Erstellung, nicht Governance nach der Erstellung.
Versionen dieser Richtung sieht man in deklarativen Enterprise-Plattformen, schema-definierten Agent-Tools, Komponenten-Katalogen und neuen Agent-zu-Interface-Protokollen wie A2UI. Das gemeinsame Muster: Agenten und Menschen komponieren aus governten Bausteinen — statt von Null an unbeschränkte Software-Oberflächen zu generieren.
Das passt auch zu dem, wie AI performt.
Long-Context-Coding-Evaluations zeigen: Performance fällt mit wachsendem Kontext. Kleinere, strukturierte Repräsentationen sind leichter zu validieren und leichter für Agenten zu manipulieren.
Der Trade-off ist Abdeckung.
Governance by Design funktioniert am besten für wiederkehrende Muster: Formulare, Tabellen, Workflows, Approvals, Reports, CRUD-Operationen, interne Tools, rollenbasierte Flows.
Schwieriger wird es bei Custom-Algorithmen, ungewöhnlichen Integrationen, untypischen Visualisierungen oder Systemen, in denen das Plattform-Modell das geforderte Verhalten nicht ausdrücken kann.
Die Frage lautet also nicht, ob Governance by Design Code ersetzt.
Sondern: Wo ist Code die falsche Abstraktion?
Für wiederkehrende Enterprise-Applikations-Oberflächen ist Code oft unnötiges Risiko. Für die verbleibende Custom-Arbeit braucht es Eskalations-Pfade.
Genau deshalb passt dieses Modell gut zu Modell 3: Governance by Design reduziert die Menge an beliebigem Code, der überhaupt existiert. Zentrale Governance kümmert sich um den Code, der übrig bleibt.

Der praktische Entscheidungs-Rahmen
Der Fehler ist, zu fragen: „Welches Modell sollen wir wählen?"
Die bessere Frage: „Welches Modell passt zu dieser Risikozone?"
Ein einfacher Entscheidungs-Rahmen:
| Frage | Wahrscheinliches Modell |
|---|---|
| Berührt es regulierte Daten, Identity, Geld oder Core Systems of Record? | Zentralisiertes Bauen |
| Ist das Problem ambig, aber das Produktionsrisiko hoch? | Dezentrale Specs, zentrales Bauen |
| Ist es ein Low/Medium-Risk-Workflow, in dem Geschwindigkeit zählt? | Dezentrales Bauen, zentrale Governance |
| Lässt es sich als Schema, Workflow, Report oder Komposition freigegebener Komponenten ausdrücken? | Governance by Design |
| Ist es Custom-Logic, die nicht in die Plattform passt? | Zentral oder dezentral mit starker Governance |
Für kleine Teams muss daraus keine Governance-Abteilung werden.
Eine leichtgewichtige Version reicht:
- Tier 0: Experimente ohne sensible Daten → jede:r darf bauen
- Tier 1: interne Tools mit limitierten Daten → frei bauen, zentrales Review vor breiterem Rollout
- Tier 2: kundenseitige oder sensible Workflows → zentraler Build oder zentrale Freigabe
- Tier 3: Core-Systeme → nur zentrales Bauen
Wichtig sind nicht die exakten Tier-Namen. Wichtig ist, dass Bau-Rechte explizit sind.
Wer darf bauen? Mit welchen Daten? Für welche User? Unter welchem Review? Wer besitzt die Wartung, sobald der Prototyp zum Workflow wird, auf den sich andere verlassen?
Genau diese letzte Frage wird in vielen Vibe-Coding-Gesprächen zu flach behandelt. Ein Prototyp wird in dem Moment zu Infrastruktur, in dem ein anderes Team sich darauf verlässt. Ein AI-generierter Workflow wird in dem Moment zum Governance-Objekt, in dem er Kundendaten, Entscheidungen oder Geld berührt.
Mein aktueller Read
Organisationen, die Vibe Coding schlicht verbieten, behalten Kontrolle — eine Weile. Aber sie schieben Experimente in inoffizielle Kanäle.
Organisationen, die nur Specs verbessern, reduzieren Übergabeverluste, aber sie heben den vollen Geschwindigkeitsvorteil nicht.
Organisationen, die dezentrales Bauen mit zentraler Governance erlauben, werden schneller — brauchen aber ernsthafte Investitionen in Policy, Review-Automatisierung und Accountability.
Organisationen, die Governance ins Erstellungsmedium bauen, bekommen den stärksten langfristigen Vorteil für wiederkehrende Muster — müssen aber akzeptieren, dass nicht alles in die Plattform passt.
Der Zielzustand ist also nicht „alle vibing freely".
Er ist unterschiedliche Bau-Rechte für unterschiedliche Risikozonen.
Das ist die organisatorische Designfrage hinter Vibe Coding: Wer darf Kontext in Software verwandeln — und unter welchen Constraints?
Teams, die das klar beantworten, werden schneller, ohne so zu tun, als sei Risiko verschwunden. Der Rest bekommt die schlechteste Kombination: inoffizielle Geschwindigkeit und offizielle Verwirrung.
Quellen
- Veracode, „2025 GenAI Code Security Report". 45% Schwachstellenrate über die getesteten AI-Coding-Aufgaben; OWASP-relevante Schwachstellen-Kategorien.
- Aikido Security, „State of AI in Security & Development 2026". Ernsthafte Vorfälle im Zusammenhang mit AI-generiertem Code; Befunde zu Security-Bypass und Reibungsverlusten bei Entwickler:innen.
- LongCodeBench / Long-Context-Coding-Evaluations. Hinweise darauf, dass Coding-Genauigkeit mit wachsender Kontextgröße und Task-Komplexität sinkt.
- Google A2UI / Agent-zu-Interface-Protokolle als Referenzrichtung für deklarative, von Agenten erzeugte Interfaces.
- Gartner Pace-Layer-Modell als Referenzrahmen für unterschiedliche Governance-Geschwindigkeiten in der Enterprise-IT.
Dr. Ronny Schüritz
Co-Founder von Build With Vibe. Technical Lead und AI-Enthusiast.
Bereit, Vibe Coding selbst auszuprobieren?
Lerne in unseren Vor-Ort-Workshops in Berlin, wie du durch KI zum Product Engineer wirst. Keine Vorkenntnisse nötig.
Workshop buchen